
SLR: Learning Quadruped Locomotion without Privileged Information
Published in Conference on Robot Learning, 2024
Abstract
The recent mainstream reinforcement learning control for quadruped robots often relies on privileged information, demanding meticulous selection and precise estimation, thereby imposing constraints on the development process. This work proposes a Self-learning Latent Representation (SLR) method, which achieves high-performance control policy learning without the need for privileged information. To enhance the credibility of the proposed method’s evaluation, SLR was directly compared with state-of-the-art algorithms using their open-source code repositories and original configuration parameters. Remarkably, SLR surpasses the performance of previous methods using only limited proprioceptive data, demonstrating significant potential for future applications. Ultimately, the trained policy and encoder empower the quadruped robot to traverse various challenging terrains
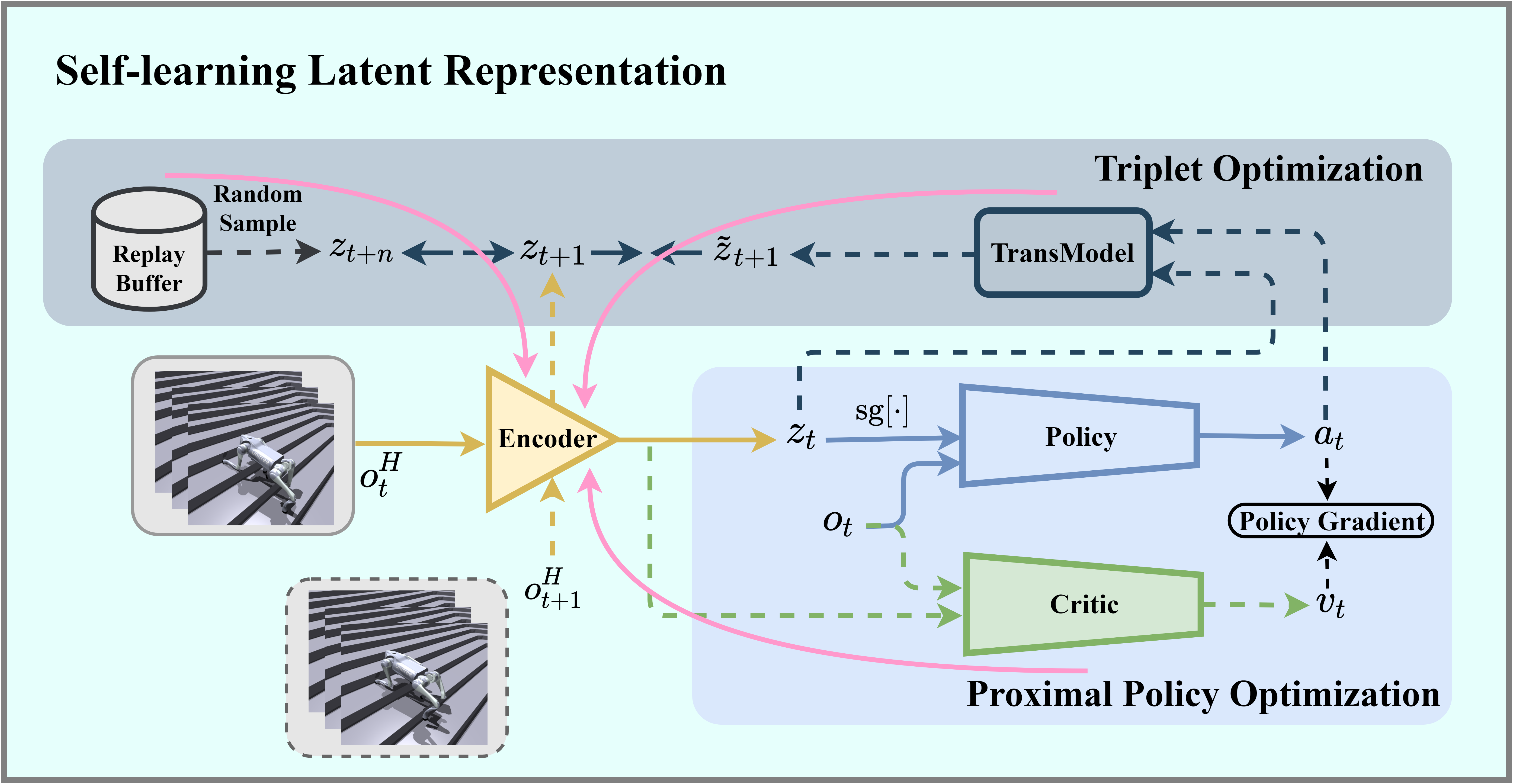
Illustration of SLR training framework. All dashed lines represent the network updating process. The solid pink line indicates the encoder updates through backpropagation from the Critic network, the transition model, and random sampling. The remaining solid lines represent the net-work’s forward inference process.